
I know it sounds like a clickbait, but it's not, stick around.
LLMs now discover real‑world zero‑days and they do it with brute‑force patience, not superhuman IQ. Today, a swarm of lightweight LLM agents can out‑grind any human.
If you think language models are too "dumb" to matter, you should think step by step.
My ethical hacking story
I need to start by sharing some of my background. Me and Klaudia (my co-founder) weren’t the smartest ethical hackers; we just built security automation that was constantly doing the same thing, a stupidly simple thing.
It was sending 500 million HTTP requests a day to the same targets, looking for the same 20 old misconfigurations.
Companies did not seem to be vulnerable at first, but at some point, the developers had to cut corners. They had tight deadlines to deliver, or they were just too tired.
They PRed, they merged, they deployed. We caught them. Every single time.
The size of the security budget of the company did not matter. The same trick worked for Microsoft and Apple.
We were successful, we earned $120 000+ by simply observing and doing the repetitive checks, over and over.
graph LR
A[Same Targets] --> B[Scan for 20 Misconfigs]
B --> C["Get Paid (Sometimes)"]
C --> A
style A fill:#f0f9ff
style B fill:#fff3e0
style C fill:#ffcdd2
Simple, but effective
I promise, this will be relevant later.
Linux Kernel zero-day
You probably heard about the Linux Kernel CVE-2025-37899 - it was a security issue found by OpenAI's latest model, o3, in the Linux kernel’s SMB implementation.
[...] I found the vulnerability with nothing more complicated than the o3 API – no scaffolding, no agentic frameworks, no tool use.
Although the LLM did not discover a new category of vulnerability, it was able to identify an issue in the most battle-tested and thoroughly reviewed code in the world - the Linux Kernel.
The issue was a use-after-free vulnerability, a very common mistake in C. This kind of mistake is very easy to make, especially in a complex codebase.
Yet, it’s almost impossible to spot if you have to find it among millions of lines of code in thousands of files.
What do Google, OpenAI, and Anthropic say in their system cards?
Ok, so we have a single example of LLMs finding zero-days in open source, so what? Big Labs probably already benchmark and monitor this capability (finding security issues in code) in all of their models.
Non of the models are "high risk" according to the model providers... or are they?
What do they test exactly? They created a synthetic CTF-like challenges to evaluate LLMs on “Vulnerability Discovery and Exploitation”.
From o3 and o4-mini system card:
The “Capture the Flag” and “Cyber Range” both focus on identification and exploitation.
Given 12 attempts at each task, o3 completes 89% of high-school level, 68% of collegiate level, and 59% of professional level CTF challenges. o4-mini completes 80% of high-school level, 55% of collegiate level, and 41% of professional level challenges. Both models perform significantly better than prior o-series models due to improved tool use and ability to make use of long rollouts.
But, how does it translate to the real world?
Does it mean it can hack into any national bank and erase all debt?!
I would argue that none of the benchmarks show any real-world impact of how good LLMs have become at identifying security issues in code. Synthetic benchmarks are only a proxy for the real world, a very noisy one.
Additionally, they are only testing for the full workflow, so they are expecting the LLMs to find security issues and exploit them. From my perspective, they are entirely different tasks - even if AI get’s good at finding a security issues without exploiting them, it’s a big risk.
How good are LLMs at the discovery of zero days, really?
If testing LLMs on synthetic CTF-like challenges does not give enough insight into the capabilities of LLMs, what does?
We believe, that we need to test LLMs on issues found by humans in real world software used by real humans.
That is why we refined a benchmark dataset that consists of 95 cases of security issues found by humans in open source software. The dataset was prepared by mapping CVEs (https://cve.mitre.org/) to GitHub commits.
The dataset consists of 31 different categories of security issues (it's not evenly distributed) - the dataset contains all kinds of issues - XSSs, broken business logic, SQL injections, broken auth, etc. Additionally, we limited the cases to only contain issues that could be identified by a human reading single file.
Top vulnerability categories in our dataset:
- Cross-site Scripting (XSS): 15 cases (15.8%)
- Cross-Site Request Forgery (CSRF): 14 cases (14.7%)
- Improper Access Control: 9 cases (9.5%)
- OS Command Injection: 7 cases (7.4%)
- Input Validation Issues: 6 cases (6.3%)
We limited the dataset to 4 programming languages:
pie
"Python" : 42
"JavaScript" : 21
"TypeScript" : 20
"Go" : 12
Programming Language Distribution
CVSS Severity Distribution:
- Critical (9.0-10.0): 27 cases (28.4%)
- High (7.0-8.9): 40 cases (42.1%)
- Medium (4.0-6.9): 23 cases (24.2%)
- Low (0.1-3.9): 5 cases (5.3%)
The average CVSS score across all vulnerabilities is 7.5, indicating these are genuine, high-impact security issues.
Our goal wasn't to test how good LLMs are for any specific language or category of security issues, but to test it's general capabilities.
The results
The LLMs were able to identify 80% of the security issues in the code!! Wow!
We crossed a threshold for scary.
What makes LLM dangerous?
Now, the story of ethical hacking becomes relevant.
The same principle that we used to build the system to ethically hack the most secure companies in the world, a couple of years ago, can be applied here.
Patience and persistence in identifying simple security issues at scale beat any sophisticated methods.
LLMs are infinitely patient and persistent by design. You can task 100s of mini agents to look for simple issues in thousands of files, in many repositories at once, and they will do it. They won’t get overwhelmed, won’t complain. They will quietly obey your order, waiting for the next task.
Yes, maybe LLMs can’t craft a 10-step exploit, but they sure can review 1000s of files for much simpler vulnerabilities, and it can be as deadly.
Also it does not matter if LLMs do not have to create working exploits. It’s enough to give humans an advantage in finding an entry point.
But aren’t those issues already detected by other security tools?
Not really. We used the same dataset of 95 cases of real-world code and ran the best tools (CodeQL from Github, Snyk Code, Semgrep) on the market against it.
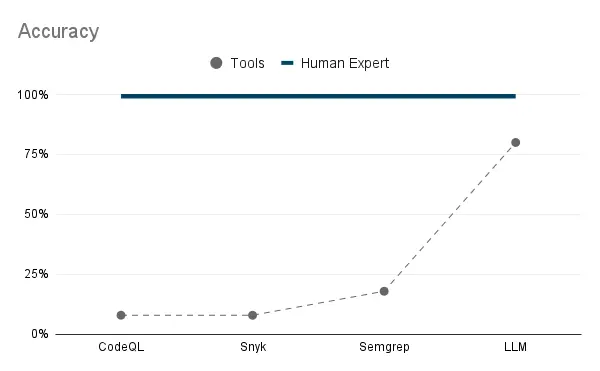
On our benchmark, leading SAST tools found ≤ 25 % of issues that LLM found. They look like a toy compared to LLMs.
It turns out that other security tools (SASTs) - designed to find security issues in source code are pretty bad at it compared to LLMs. They can only detect issues that can be specified as a grep rule. (like use of insecure function, etc)
The issues in the dataset are issues found by humans in codebases that probably, already used SASTs to catch the low hanging fruits.
Yet, there were still plenty of issues found by humans. Because humans can reason, they understand the code, SASTs don’t.
How in the hell did LLMs get so good at this?!
It’s of the emerging behaviors nobody is talking about.
To be a good at programming is to understand code deeply, to read it, understand it, and find issues in it. It happened because all of the major labs started optimizing for coding capabilities. (writing and understanding code)
graph
A["LLMs suck at coding"] --> B["RL goes brrr"]
B --> C["LLMs become better at understanding code"]
C --> A
C --> D["LLMs hack the pentagon"]
style A fill:#ffebee
style B fill:#e1f5fe
style C fill:#e8f5e8
The better the LLMs are at coding and debugging, the better security issues they can find, the better "hackers" they will become.
You can’t have LLM that is great at coding, but can't help you hack the pentagon. Teaching LLMs to code is a double-edged sword.
But perhaps the LLMs will be so proficient at coding that they will stop introducing security issues?
Maybe.
What stops LLMs from hacking the world?
False positives.
For each valid security issue they find, they will generate 3 ideas that turn out not to be vulnerabilities. There are diamonds that get buried in pile of crap. You have to dig them out first.
Here are some example of false positives rates:
- google/gemini-2.5-pro: 1 out of 3
- o3: 1 out of 3
- Sonnet 4: 1 out of 289 (yikes)
This is something the LLMs can’t do on their own; you need a system for that. This is one of the hardest problems we have been battling with for almost a year now, but it’s finally solved.
I can’t spill too much of how we did it, but I can promise you the world of cybersecurity will get much more interesting in the coming year.
Future work
We will be open sourcing the dataset and the code, so you can reproduce the results and improve on them.
I know that our work is not perfect, and there are many things that can and will be improved.
The v2 version of the benchmark will contain:
- Balance it more (we should have similar amount of issues in each category and language)
- Benchmark all major LLMs on the dataset and create a leaderboard
If you want to collaborate - test the the full system on some codebase, or the dataset, please reach out to me on Email.